
Google Cloud の HTAP 対応データベースの分析機能のアーキテクチャの違いについて調査しました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
ウィスキー、シガー、パイプをこよなく愛する大栗です。
Google Cloud における HTAP を実現する RDBMS は AlloyDB や Spanner があります。この 2 つのデータベースについて分析ワークロードへの対応方針をまとめてみます。
本エントリは HTAPデータベース Advent Calendar 2024 の 23 日目だったはずのものです。
Google Cloud における HTAP
近年はデータ分析がビジネス上より重要になってきており、リアルタイムでミッションクリティカルな場面でも分析ワークロードが必要になる要件が発生するようになってきています。そのようなワークロードに対応するアーキテクチャをガートナー社の 2014 年のレポートで Hybrid transaction/analytical processing (HTAP) と呼んでいます。
Google Cloud のデータベースは多種に渡りますが、トランザクションと分析のハイブリット処理を行えるものは多くありません。トランザクションと分析のワークロードを1つのデータベースで対応できるものは、AlloyDB、Spanner、Bigtable の 3 種です。本エントリではリレーショナルモデルのみを扱うこととし、AlloyDB と Spanner について論じます。
AlloyDB のカラム型エンジンとは
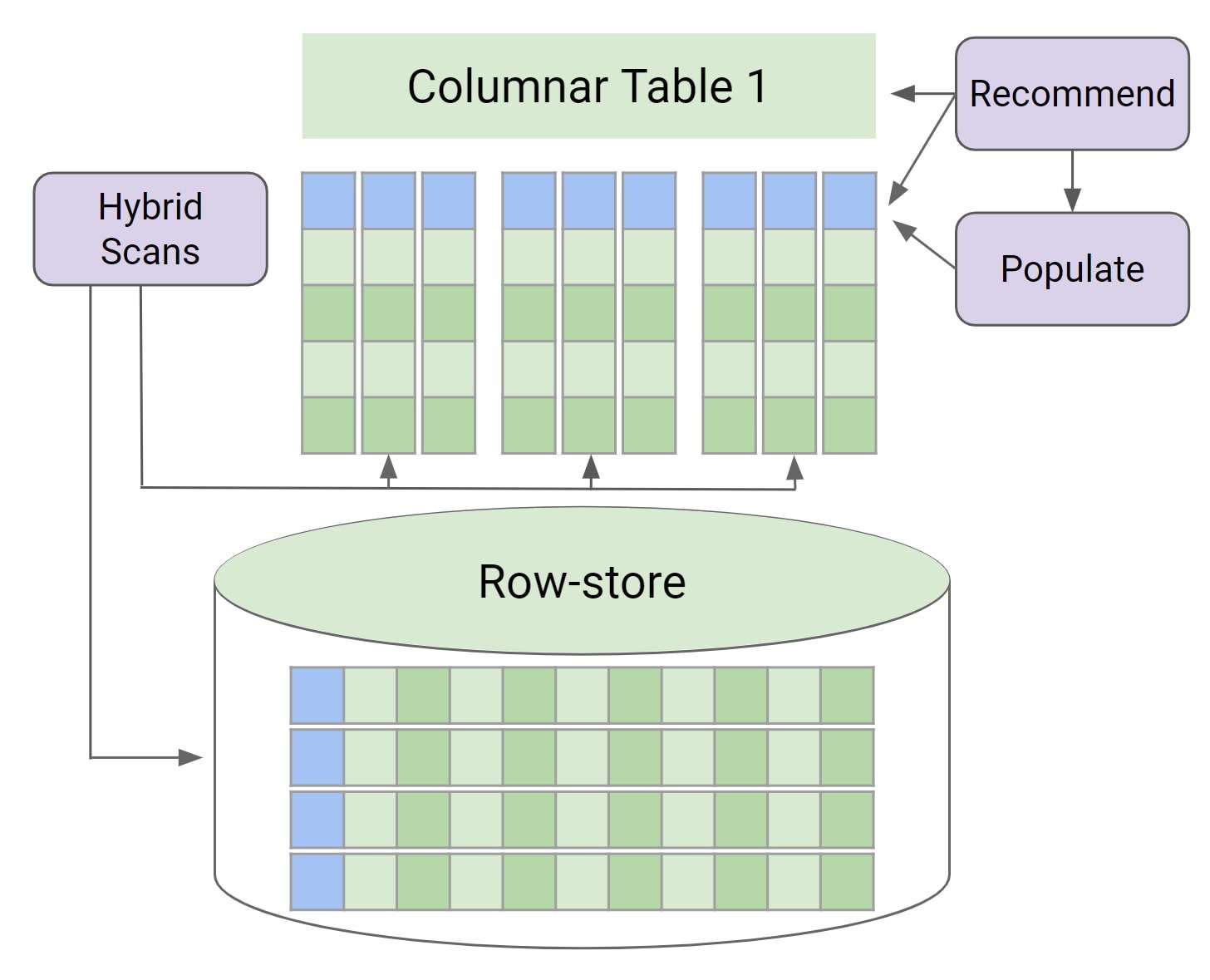
AlloyDB for PostgreSQL は高いパフォーマンスや高速な分析クエリが特徴の PostgreSQL 互換データベースです。標準の PostgreSQL と比較して 4 倍高速だと主張しています。分析クエリを高速に実行するためにカラム型エンジンを備えています。
カラム型エンジンは、メモリ上の列ストアと列ストアを使用するクエリプランナー及び実行エンジンを提供します。列ストアはカーディナリティが低い場合に行ストアに比べデータサイズの効率が良く高速にデータを読み込むことが可能になります。ワークロードを自動で分析して列ストアを使用すべきテーブルに適用します。またクエリに応じて行ストアか列ストアのどちらを使用するか実行計画を立て、テーブルの結合にハッシュ結合の代わりにベクトル化結合[1]を使用できます。
Pros
AlloyDB のカラム型エンジンは普通に PostgreSQL を使用するのと変わらずに分析クエリ実行時に自動的に適用され、高速に結果が返されます。そのため利用者側は分析クエリをあまり意識せずとも恩恵を受けられます。
Cons
列ストアはメモリ上に展開されるため、インスタンスのサイズに応じてデータ量が制限されます。そのため分析クエリを高速に実行させるために、トランザクションワークロードには過剰なサイズのインスタンスが必要になる場合が考えられます。
Spanner Data Boost とは
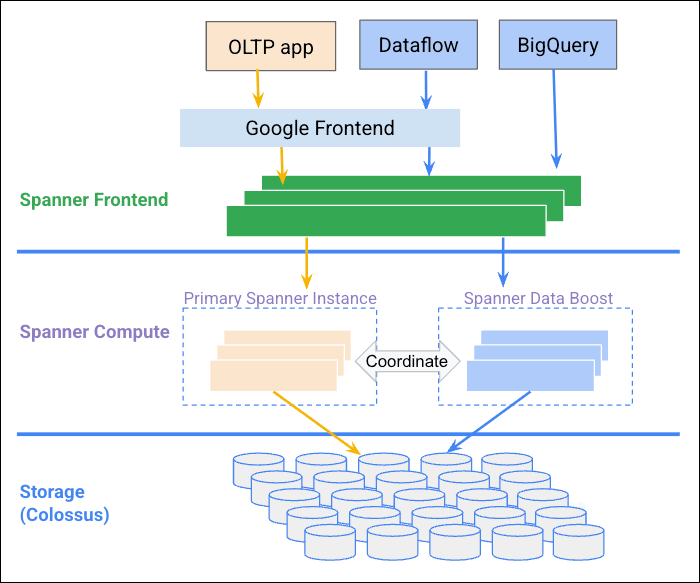
Spanner は読み書きに制限のないスケーラビリティを有しつつ、マルチリージョンでも外部整合性を提供するデータベースです。分析ワークロードに対応するために Data Boost という機能が提供されています。
Spanner Data Boost は既存のトランザクションワークロードに影響を与えないために、独立したコンピューティングリソースを提供します。Spanner はAPI を受ける Google Frontend の後ろに、Spanner Instance へのルーティングを司る Spanner Frontend を経由して Spanner のコンピューティングリソースへアクセスします。Data Boost は分析クエリを実行するときに Spanner Instance へアクセスするのではなく分析専用の追加のコンピューティングリソースへルーティングされるため既存トランザクションを実行するリソースにはほとんど影響を与えません。Data Boost を利用する場合には、パーティション化クエリ実行時に data_boost_enabled パラメータを指定する必要があります。
Pros
Data Boost はフルマネージドのサーバーレス サービスであるため、Spanner の過剰なプロビジョニングが必要ありません。
Cons
Data Boost を利用するにはパラメータで指定する必要があるため、アプリケーション側で分析クエリを実行することを意識する必要があります。
まとめ
Google Cloud ではリレーショナルデータベースとして HTAP に対応したものが2個ありますが、各々分析クエリを処理するためのアーキテクチャの考え方が異なります。
AlloyDB ではメモリ上に列ストアを展開して分析クエリに対応します。Spanner では分析専用のコンピュートリソースをサーバーレスに提供して分析クエリに対応します。これはトラディショナルなデータベースの延長である AlloyDB は中央で処理を行い、分散データベースである Spanner はワークロードを分散して追加のリソースを使用するというデータベースの設計方針の違いが出ているのではないかと思いました。
さいごに
HTAPデータベース Advent Calendar 2024 に遅れてしまいました。ごめんなさい。
re:Invent などで Amazon Aurora の本格的な HTAP 対応[2]のアップデートがあるのではと期待していたのですが、Aurora DSQL という異なる路線のアップデートであったので Google Cloud ネタで書いてみました。










